在上一篇文章《微信小程序“反编译”实战(一):解包》中,我们详细介绍了如何获取某一个小程序的 .wxapkg 包,以及分析了 .wxapkg 包的结构,最后通过脚本解压获取包中的文件:小程序“编译”后的代码文件和资源文件,但是由于这些文件大部分被混淆了,可读性很差,所以本文将进一步分析,尽可能地把 .wxapkg 包的内容还原为“编译”前的内容。
注:本文包含一部分源码分析,由于手机屏幕较小,阅读体验可能不佳,建议在电脑上浏览。
特别感谢:下文使用的还原工具来自于 GitHub 上的开源项目 wxappUnpacker,在此特别感谢原作者的无私贡献。
概览
我们知道,前端 Web 网页编程采用的是 HTML + CSS + JS 这样的组合,其中 HTML 是用来描页面的结构,CSS 用来描述页面的样子,JS 通常用来处理页面逻辑和用户的交互。类似地,在小程序中也有同样的角色,一个小程序工程主要包括如下几类文件:
.json后缀的 JSON 配置文件.wxml后缀的 WXML 模板文件.wxss后缀的 WXSS 样式文件.js后缀的 JavaScript 脚本逻辑文件
例如“知识小集”的小程序源码工程结构如下:
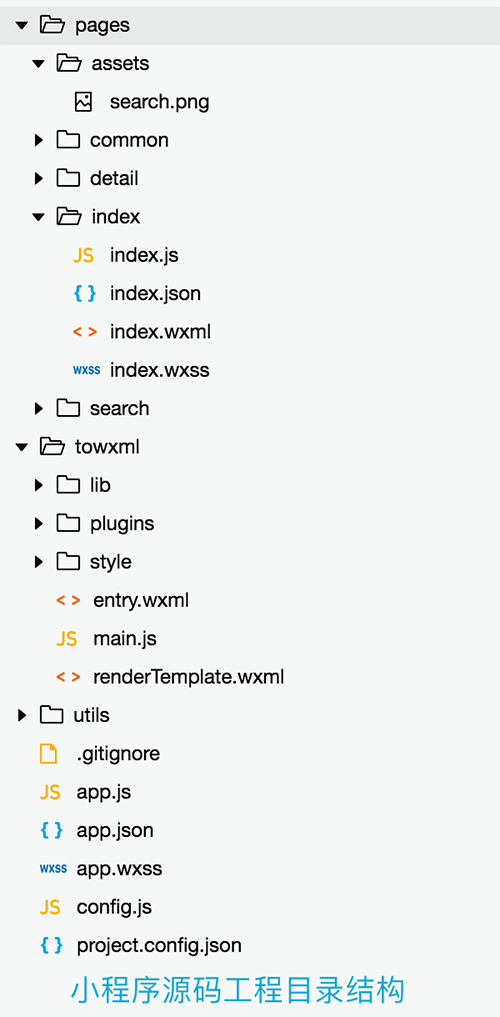
然而,根据上一篇文章介绍,对“知识小集”小程序的 .wxapkg 解包后得到如下文件:
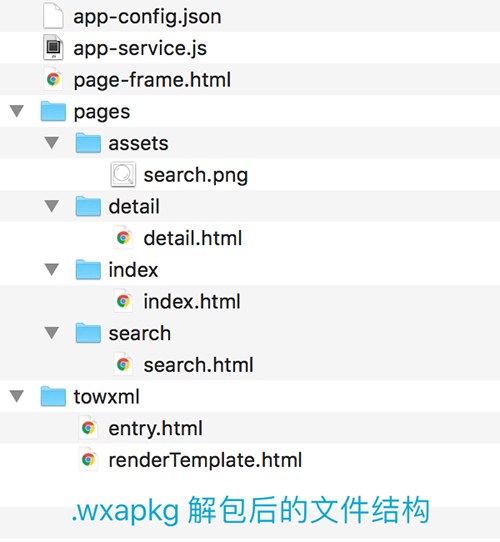
主要包括 app-config.json, app-service.js, page-frame.html, *.html, 资源文件 等,但这些文件已经被“编译混淆”并重新整合压缩,微信开发者工具并不能识别它们,我们无法直接对它们进行调试/编译运行。
所以,我们先尝试分析一下从 .wxapkg 提取出来的各个文件内容的结构及其用途,然后介绍如何用脚本工具把它们一键还原为“编译”前的源码,并在微信开发者工具中跑起来。
文件分析
本节主要以“知识小集”小程序的 .wxapkg 解包后的源码文件为例,进行分析。
你也可以跳过本节的分析,直接看下一节介绍用脚本“反编译”还原源码。
app-config.json
小程序工程主要包括工具配置 project.config.json,全局配置 app.json 以及页面配置 page.json 三类 JSON 配置文件。其中:
project.config.json 主要用于对开发者工具进行个性化配置以及包括小程序项目工程的一些基础配置,所以它不会被“编译”到 .wxapkg 包中;
app.json 是对当前小程序的全局配置,包括了小程序的所有页面路径、界面表现、网络超时时间、底部 tab 等;
page.json 用于对每一个页面的窗口表现进行配置,页面中配置项会覆盖 app.json 的 window 中相同的配置项。
因此“编译”后的文件 app-config.json 其实就是 app.json 和各个页面的配置文件的汇总,它的内容大致如下:
1 | { |
通过与原工程 app.json 和各页面配置 page.json 内容的对比,我们可以得出 app-config.json 汇总文件的简单整合规律,很容易把它拆分成“编译”前对应的各 json 文件。
app-service.js
在小程序项目中 JS 文件负责交互逻辑,主要包括 app.js,每个页面的 page.js,开发者自定义的 JS 文件和引入的第三方 JS 文件,在“编译”后所有这些 JS 文件都会被汇总到 app-service.js 文件中,它的结构如下:
1 | // 一些全局变量的声明 |
在这个文件中,原有小程序工程中的每个 JS 文件都被 define 方法定义声明,定义中包含 JS 文件的路径和内容,如下:
1 | define("path/to/xxx.js", function(...){ |
因此,我们同样很容易提取这些 JS 文件源码,并恢复至相应的路径位置中。当然,这些 JS 文件中的内容经过混淆压缩,我们可以使用 UglifyJS 这样的工具进行美化,但仍很难还原一些原始变量名,不过基本不影响正常阅读和使用。
page-frame.html
在小程序中使用 WXML 文件描述页面的结构,WXSS 文件描述页面的样式。工程中有一个 app.wxss 文件用于定义一些全局的样式,会自动被 import 到各个页面中;另外每个页面也都分别包含 page.wxml 和 page.wxss 用于描述其页面的结构和样式;同时,我们也会自定义一些公共的 xxxCommon.wxss 样式文件和公共的 xxxTemplate.wxml 模板文件供一些页面复用,一般在各自页面的 page.wxss 和 page.wxml 中去 import。
当“编译”小程序后,所有的 .wxml 文件和 app.wxss 及公共 xxxCommon.wxss 样式文件的将被整合到 page-frame.html 文件中,而每个页面的 page.wxss 样式文件,将分别单独在各自的路径下生成一个 page.html 文件。
page-frame.html 文件的内容结构如下:
1 |
|
相比其他文件,page-frame.html 比较复杂,微信把 .wxml 和部分 .wxss 直接“编译”并混淆成 JS 代码放入上述文件中,然后通过调用这些 JS 代码来构造 Virtual-Dom,进而渲染页面。
其中最核心的是 $gwx 和 setCssToHead 这两个方法。
$gwx 用于通过 JS 代码生成所有 .wxml 文件,其中每个 .wxml 文件的内容结构都在 $gwx 方法中被定义好并混淆了,我们只要传给它页面的 .wxml 路径参数,即可获取到每个 .wxml 的内容,再简单加工一下即可还原成“编译”前的内容。
在 $gwx 中有一个 x 数组用于存储当前小程序都有哪些 .wxml 文件,例如,“知识小集”小程序的 x 值如下:
1 | var x = ['./pages/detail/detail.wxml', '/towxml/entry.wxml', './pages/index/index.wxml', './pages/search/search.wxml', './towxml/entry.wxml', '/towxml/renderTemplate.wxml', './towxml/renderTemplate.wxml']; |
此时我们可以在 Chrome 中打开 page-frame.html 文件,然后在 Console 中输入如下命令,即可得到 index.wxml 的内容(输出一个 JS 对象,通过遍历这个对象即可还原出 .wxml 的内容)
1 | $gwx("./pages/index/index.wxml") |
setCssToHead 方法用于根据几段被拆分的样式字符串数组生成 .wxss 代码并设置到 HTML 的 Head 中,同时,它还将所有被 import 引用的 .wxss 文件(公共 xxxCommon.wxss样式文件)所对应的样式数组内嵌在该方法中的 _C 变量中,并标记哪些文件引用了 _C 中数据。另外在 page-frame.html 文件的末尾,调用了该方法生成全局 app.wxss 的内容设置到 Head 中。
因此,我们可以在每个调用 setCssToHead 方法的地方提取相应 .wxss 的内容并还原。
对于 page-frame.html 文件中 $gwx 和 setCssToHead 这两个方法更详细的分析,可以参考这篇文章。
此外,checkDeviceWidth 方法顾明思议,用于检测屏幕的宽度,其检测结果将用于 transformRPX 方法中将 rpx 单位转换为 px 像素。
rpx的全称是responsive pixel,它是小程序自己定义的一个尺寸单位,可以根据当前设备屏幕宽度进行自适应。小程序中规定,所有的设备屏幕宽度都为750rpx,根据设备屏幕实际宽度的不同,1rpx所代表的实际像素值也不一样。
*.html
上面提到,每个页面的 page.wxss 样式文件,“编译”后将分别在各自的所在路径下生成一个 page.html 文件,每个 page.html 的结构如下:
1 | <style></style> |
在该文件中通过调用 setCssToHead 方法将 .wxss 样式内容设置到 Head 中,所以同样地,我们可以根据 setCssToHead 的调用参数提取每个页面的 page.wxss。
资源文件
小程序工程中的图片、音频等资源文件在“编译”后将直接被拷贝到 .wxapkg 包中,其原始的路径也保留不变,因此我们可以直接使用。
“反编译”
在上一节,我们完成了 .wxapkg 包几乎所有文件内容的简要分析。现在我们介绍一下如何通过 node.js 脚本帮我们还原出小程序的源码。
在这里需要再次感谢 wxappUnpacker 作者提供的还原工具,让我们可以“站在巨人的肩膀上”轻松地去完成“反编译”。它的使用如下:
node wuConfig.js <path/to/app-config.json>: 将app-config.json中的内容拆分成各个页面所对应的page.json和app.json;node wuJs.js <path/to/app-service.js>: 将app-service.js拆分成一系列原先独立的JS文件,并使用Uglify-ES美化工具尽可能将代码还原为“编译”前的内容;node wuWxml.js [-m] <path/to/page-frame.html>: 从page-frame.html中提取并还原各页面的.wxml和app.wxss及公共.wxss样式文件;node wuWxss.js <path/to/unpack_dir>: 该命令参数为.wxapkg解包后目录,它将分析并从各个page.html中提取还原各页面的page.wxss样式文件;
同时,作者还提供了一键解包并还原的脚本,你只需要提供一个小程序的 .wxapkg 文件,然后执行如下命令:
1 | node wuWxapkg.js [-d] <path/to/.wxapkg> |
此脚本就会自动将 .wxapkg 文件解包,并将包中相关的已被“编译/混淆”的文件自动地恢复原状(包括目录结构)。
PS: 此工具依赖 uglify-es, vm2, esprima, cssbeautify, css-tree 等 node.js 包,所以你可能需要 npm install xxx 安装这些依赖包才能正确执行。
更详细的用法及相关问题请查阅该开源项目的 GitHub repo。
最后,我们在 微信开发者工具 中新建一个空小程序工程,并将上述还原后的相关目录文件导入工程,即可编译运行起来,如下图为“知识小集”小程序 .wxapkg 还原后的代码工程:
以上,大功告成!
总结
本文详细分析了 .wxapkg 解包后的各文件结构,并介绍了如何通过脚本“一键还原”得到任意小程序的源码。
对于一些简单的,且使用微信官方介绍的原生开发方式开发的小程序,用上述工具基本可以直接还原得到可运行的源码,但是对于一些逻辑复杂,或者使用 WePY、Vue 等一些框架开发的小程序,还原后的源码可能会有一些小问题,需要我们人肉去分析解决。
后续
本文对小程序源码“编译”后的各文件内容结构及用途的分析相对比较零散,而且没有对各文件的依赖关系及加载逻辑进行研究,后续我们再写一些文章讲解微信客户端是如何解析加载小程序 .wxapkg 包并运行起来。